Composition and collective performative practice
Score for vocal interaction (2023)
The score was developed for a collective performative investigation of voice interfaces and vocal interaction with smart speakers at VEGA LAB March 2023.

The composition consist of a score for interactions with smart speakers and cards for vocal performative interactions. Below are two examples of the performative interaction cards.
![]()
![]()
Collective performative vocal interaction with smart speakers
![]()
![]()
Composition for collective listening (2023)
The score was developed for a collective performative investigation of collective listening at VEGA LAB March 2023.
![]()
![]()
For more than one voice (2016 - )
For More Than One Voice is a collective grounded in collective performative readings which has manifested as performances, workshops and scores. The collective explores the politics and aesthetics of vocal expression in groups and collectives. The collective performative readings investigates more specifically,how we might speak and listen to more than one voice in ways that allow resonance, polyphony, dissonance, ambiguity, plurality and embrace.
The collective performative reading has been performed at NLH Space as part of Stemmer (2016) curated by Mette Garfield and Miriam Wistreich, at Den Frie Udstillingsbygning as part of Scripted (2016), edited and organized by Trine Mee Sook Gleerup, Maria Bordorff and Mathias Kryger in collaboration with Eller med a, and at Sorte Firkant convened by Migratory Times, the Institute of (im)Possible Subjects, For More Than One Voice, and at land’s edge (2016). A remediation of the collective performative reading was published in Collective (special issue at Peripeti, 2020). In 2021 we did a mediated collective performative reading via Zoom at the Media School, The Royal Academy of Fine Arts and published a score on 1000 Scores. In 2022 a workshop on event scores with starting piont in our score on 1000 Scores was held at the Rythmic Music Conservatory (RMC).
For more than one voice is a collaboration with artist Jane Jin Kaisen.






Composition For More Than One Voice (2021)

Performance



Photo credit: Frida Gregersen
Performance documentation, NLHspace 2016.
Read more about the collective performative reading here
[multivocal] (2015 - 2022)
[multi’vocal] was a collective exploring the politics and aesthetics of synthetic voices. The collective was concerned with the collection and generation of multivocal synthetic voices and the project has manifested as sonic interactions design, installations and events.
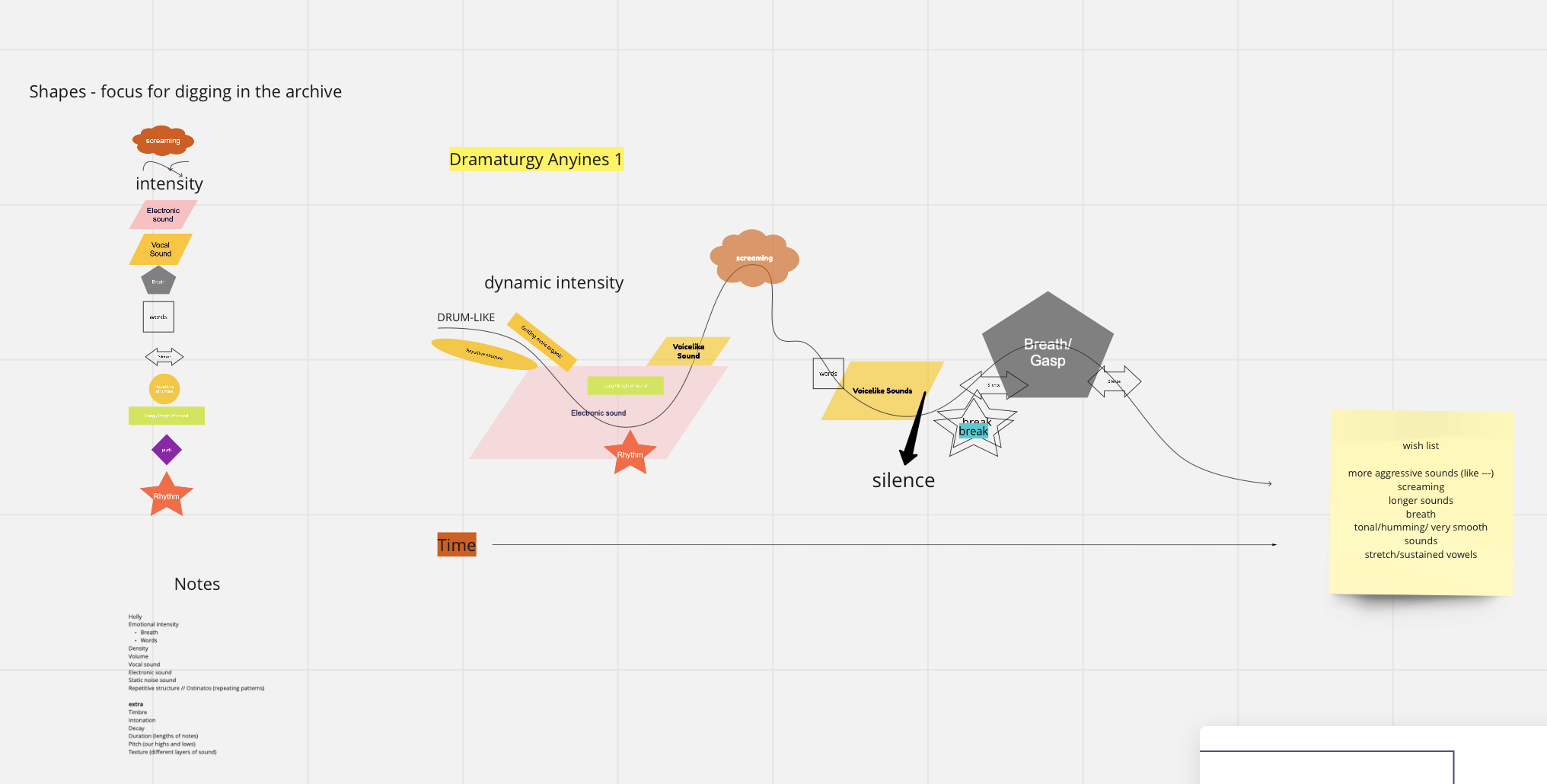
Generating the voice
In a collaboration between [multi’vocal] and Anyines record label, a onesided LP with the generation of the tone of a synthetized voice will be released in the future. Below are some process documentation of the compositional collective work on the score for the record.
Score